GraphQL Mutations
📖 Click here for a fully-worked example of the code in this blog post
In this post I will continue the development of a GraphQL endpoint. So far it is able to return the developers, projects and skills for a fictitious software consultancy firm. In past posts I've developed the initial schema, added a SQLite database and then added the ability to make queries more selective with arguments. These changes have all been one-way as they all relate to retrieving data. Many APIs support the ability to write data too - in REST this is a simple HTTP POST action. Let's now take a look at how GraphQL addresses this - using mutations.
A GraphQL schema has a root Query type, where you define the top-level queries. Mutations are very similar to queries: they have a name, they accept arguments (known as inputs) and then they return some data of a given type. The main difference is that mutations are performing a write operation, immediately followed by a read. By convention a mutation returns the data that was affected during the write.
Just like queries, for each mutation you define GraphQL will call a function. This means that there's no actual restriction on a query from performing a write - the distinction only exists in your schema. A mutation is actually a query, but it's doing something else first. By separating out pure reads into a Query type and writes into a Mutation type, it makes it clear to the user what they can expect to happen when invoking your GraphQL endpoint.
I'm going to be defining mutations that broadly fit within three categories. I won't cover every single mutation in this post, instead I'll address some of the more interesting ones within each category. You'll be able to inspect the source code if you'd like to see the complete set.
- Mutations that add data - a developer, a project, a skill
- Mutations that delete data - a developer, a project
- Mutations that update data - assigning a project, changing a developer's role, updating a developer's competencies
Inputs
Let's cover input types in a broad sense. Unlike REST, GraphQL expresses a type system via its schema. In the previous posts I introduced the concept of arguments that can passed into a query. Mutations combine the type system and argument capabilities as a way of defining what data a mutation is expecting to be supplied.
However, the types that you can define on a mutation are more restrictive. This is to prevent the possibility for circular dependencies. Only scalars (Int, String, Boolean, Enums, etc) are accepted. If you wish to define a complex argument, it must be defined as a special input type, whose fields are restricted to scalar values. You can also use the ! operator to define a field as mandatory.
By convention all of my mutations accept one mandatory argument, named input. It is an input type and it defines all of the data that's expected for that mutation. It may seem like overkill when there's just one piece of data required, but I've chosen to do this for consistency.
I define the root Mutation type on my schema, alongside an input type for each mutation:
schema.js
input DeveloperInput {
name: String!,
role: Role!
}
input DeleteDeveloperInput {
id: String!
}
input ProjectInput {
name: String!,
description: String!
}
input DeleteProjectInput {
id: String!
}
input SkillInput {
name: String!
}
input AssignCompetencyInput {
developer: String!,
skill: String!,
rating: Int!
}
input AssignProjectInput {
developer: String!,
project: String!
}
input AssignRoleInput {
developer: String!,
role: Role!
}
type Mutation {
addDeveloper(input: DeveloperInput!) : Developer,
deleteDeveloper(input: DeleteDeveloperInput!) : String,
addProject(input: ProjectInput!) : Project,
deleteProject(input: DeleteProjectInput!) : String,
addSkill(input: SkillInput!) : Skill,
assignCompetency(input: AssignCompetencyInput!) : Developer,
assignProject(input: AssignProjectInput!) : Developer,
assignRole(input: AssignRoleInput!) : Developer
}As you'd expect by this point, each mutation is just another function call that is defined on my resolver object. Notice how these are just calling through to functions that I will implement in my api.js file.
schema.js
export const rootValue = {
developer: ({ id }, ctx) => getDeveloper(ctx, id),
developers: ({ assigned }, ctx) => getDevelopers(ctx, assigned),
project: ({ id }, ctx) => getProject(ctx, id),
projects: (obj, ctx) => getProjects(ctx),
skill: ({ id }, ctx) => getSkill(ctx, id),
skills: ({ order }, ctx) => getSkills(ctx, order),
addDeveloper: ({ input }, ctx) => createDeveloper(ctx, input),
deleteDeveloper: ({ input }, ctx) => removeDeveloper(ctx, input),
addProject: ({ input }, ctx) => createProject(ctx, input),
deleteProject: ({ input }, ctx) => removeProject(ctx, input),
addSkill: ({ input }, ctx) => createSkill(ctx, input),
assignCompetency: ({ input }, ctx) => setCompetency(ctx, input),
assignProject: ({ input }, ctx) => setProject(ctx, input),
assignRole: ({ input }, ctx) => editRole(ctx, input)
};Invoking a mutation requires you to first state that you're performing a mutation, followed by the name of the mutation. This is a slightly more verbose syntax than just making a simple query:
mutation {
addDeveloper(input: {
name: "Colin",
role: LEAD
}) {
id,
name,
role
}
}As they're part of the schema, interactive environments like GraphiQL are able to provide auto-completion!
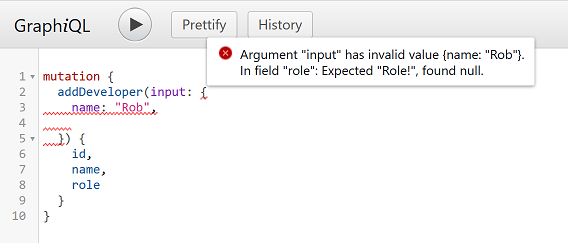
Addition Mutations
Time to drill down into how some of these mutations are implemented.
Adding a Developer
When it comes to adding a developer, I'm only asking for some of the fields that are defined on the Developer type: namely a role and a name. I'm assuming that it is unlikely that project assignment will happen immediately and that it will be up to the developer at a later point to update their list of competencies (where I work, this is arranged via a periodic staff survey). So, I define a function to perform an INSERT operation into the database. This will auto-generate an id by incrementing from the last used ID.
As a mutation is a write and then a read, I also need to make this function return something. Database functions are Promise-based in node-sqlite, so I am able to chain a function to do a read onto the function that performed the write. When Promises are chained in this way, the result of one function is passed to the next in the chain. The result object returned from the write function contains a lastID field that's set to the id of the new item. I already have functions to lookup by an ID, so this can be invoked. Should something go wrong with the insertion, then I'd need to report an error back to the caller. The result object from the database also contains a changes field. If this is zero, the operation was unsuccessful. I rerturn an Error in this scenario, which rejects the Promise:
export const createDeveloper = (ctx, developer) =>
ctx.db.run('INSERT INTO developer (name, role) VALUES (?, ?)', developer.name, fromRole(developer.role))
.then(result => result.changes ?
getDeveloper(ctx, result.lastID) :
new Error('Unable to create developer'));The role of a developer is specified as an enum. GraphQL enums are string-based (so the Role type has the allowed values of GRAD, DEV, SENIOR, LEAD). In SQL these are stored as integer values, so I also had to define a helper function fromRole which converted the enum from a String to an Int.
A quick note about security. While the GraphQL validation layer is checking that the name of the developer is a String, it is not performing any further validation on the string itself, such as whether it's a sensible string to store in the database as-is. In a production system I'd remain hesitant and perform my own validation before storing it in the database. SQL injection attacks are remarkably still one of the top 10 attack vectors for applications. GraphQL is adding little, by default, towards solving SQL injection. This is deliberate - GraphQL makes no assumptions about where your data are coming from. Although, it is possible to define further restrictions with custom types.
Adding a Skill
A skill is something that a developer can possess. In the database the competencies table represents an association between a developer and a skill. As a developer I could say that I possess the C# skill, and I'd rate myself as 8/10 on that front. It doesn't make sense for us to have two skills named C#, so I'd like for it not to be possible to have a duplicate skill.
Unfortunately I made a mistake by not adding this as a constraint to the database up-front. This is fixed by defining a new migration file, which adds the unique constraint. At startup the migration files are executed sequentially. Up until this point all the data are static, so I'm comfortable making this change:
002-skills-unique-names.sql
-- Up
CREATE UNIQUE INDEX skill_name ON skill(name)
-- Down
DROP INDEX skill_nameA SQL constraint violation is naturally an error. node-sqlite will reject the promise outright when this happens:
export const createSkill = (ctx, skill) =>
ctx.db.run('INSERT INTO skill (name) VALUES (?)', skill.name)
.then(result => result.changes ?
getSkill(ctx, result.lastID) :
new Error('Unable to create skill'),
() => new Error('Unable to create skill'));Deletion Mutations
Deletion operations are straightforward - they're just DELETE calls into the database. The foregin key constraints on the table will handle cascade the delete onto tables that contain derived data. Deleting a developer therefore will also delete the entry in the assignments table (if they're assigned to a project) and remove all their competencies.
The interesting question is what is a sensible thing to return. Some prefer to return the deleted item - although be careful doing that, as your database might perform further lookups using an id that's no longer present. I prefer to return the id of the deleted item.
For deleting a project, this looks like:
export const removeProject = (ctx, { id }) =>
ctx.db.run('DELETE FROM project WHERE id = $id', { $id: id })
.then(result => result.changes ?
id :
new Error(`Unable to delete project with id ${id}`));Update Mutations
This is where things get interesting! I've defined three update mutations and as they're a bit more complicated in nature than the basic additions or deletions, allow me to cover each one individually.
Updating a Developer's Role
Promoting or demoting a developer is a case of asking the caller to provide the id of the developer alongside the new Role which they'd like to have. As Role is an enum, it's scalar and therefore permitted to be used in a GraphQL input type. The entire developer object is then retrieved from the database and returned to the caller.
export const editRole = (ctx, roleChange) =>
ctx.db.run('UPDATE developer SET role = $role WHERE id = $id', { $role: fromRole(roleChange.role), $id: roleChange.developer })
.then(result => result.changes ?
getDeveloper(ctx, result.lastID) :
new Error(`Unable to edit role ${roleChange.role} for develoepr ${roleChange.developer}`));Assigning a Project
The input for this mutation is simple, requiring a developer's id and the project id.
The complexity with this mutation is that I have to be careful of the fact that a developer may already be assigned to a project. Therefore it is not possible to run a straightforward UPDATE statement, as above. SQLite supports the INSERT OR REPLACE operation, which will update an existing entry in a table if there is already a matching entry in the table. Otherwise it will add a new entry.
export const setProject = (ctx, assignment) =>
ctx.db.run('INSERT OR REPLACE INTO assignments (developerId, projectId) VALUES (?, ?)', assignment.developer, assignment.project)
.then(result => result.changes ?
getDeveloper(ctx, result.lastID) :
new Error(`Unable to assign developer ${assignment.developer} to project ${assignment.project}`));Assigning a Competency
To assign a competency, the user will specify a developer's id, a skill id and a rating. There is a similar problem to above, where a competency may already exist. Perhaps a developer has attended a training course and wishes to claim they're now more knowledgeable at C#. They may also have recently developed a new skill (let's say F#) and wishes to tell the company about that. I use the INSERT OR REPLACE operation for this scenario:
export const setCompetency = (ctx, assignment) =>
ctx.db.run('INSERT OR REPLACE INTO competencies (developerId, skillId, value) VALUES (?, ?, ?)', assignment.developer, assignment.skill, assignment.rating)
.then(result => result.changes ?
getDeveloper(ctx, assignment.developer) :
new Error(`Unable to assign developer ${assignment.developer} to skill ${assignment.skill}`));Next Steps
This GraphQL endpoint is developing quite the feature set now. It's possible to imagine a range of line-of-business applications that all speak to this one GraphQL endpoint to update the business' data. A HR web application could be responsible for adding developers to the staff roster. A client management application could then be responsible for managing the list of projects and assigning staff to these projects.
However, for it to be truly representative, let's say that we only want to enable client managers to add projects, and we only want HR to be able to add staff. This is a pretty interesting challenge and I'll cover how to achieve it in the next part of the blog series.