Getting Started with GraphQL
📖 Click here for a fully-worked example of the code in this blog post
GraphQL is a "query language for APIs". Rather than a web service exposing static, predefined REST endpoints, it instead exposes a single endpoint that is capable of:
- Receiving, interpreting and responding to incoming requests for data
- Handling requests to manipulate (mutate) data
- Expressing the capabilities of the server, through a queryable type system.
GraphQL is itself a language-independent specification, with implementations existing in many programming languages. In this blog series, I will build a GraphQL server with NodeJS, using the "reference implementation" of a GraphQL server.
Motivation
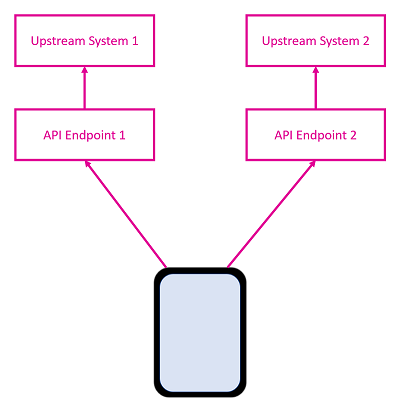
While developing an application, I was assigned a task that required me to retrieve some information from the server. Unfortunately, the API endpoint we were already using did not provide this additional piece of required data. I had to call a different API endpoint, meaning another round trip to the server. On the client-side, I then had to write and maintain code to orchestrate multiple requests and stitching together the responses into a meaningful responses. When you consider handling the various failure modes, this becomes a reasonably complicated chunk of code, which isn't particularly efficient from a networking perspective.
The reason that we had two different APIs for the same domain object was largely a product of history, with each individual endpoint reaching out to a different system upstream and simply proxying the result back. Not particularly atypical within large enterprises.
It also meant that one of the API calls was oversharing - returning more information than the client actually needed, whilst the other was undersharing - because we had to go elsewhere for some extra properties.
One potential solution is to create a new REST endpoint that does all this for us, only returning the information that my application needed. Whilst this is a step in the right direction, removing the under/oversharing problem, reducing the round trips to one, and removing the need for the UI code, this isn't maintainable. The next time another app comes along, it may also have different data requirements.
GraphQL aims to replace multiple REST calls with a single call to an endpoint. You ask for only the data that you need, and the server responds with that data only. Responses are in JSON format, matching closely with the format of the query request. The GraphQL server is responsible for coordinating with upstream systems, databases etc, and responding appropriately. This creates a clear separation of concerns between client and server, whilst creating a single point of responsibility for callers of your server. This can be of great benefit in environments with high latency, or limited/sporadic network availability..
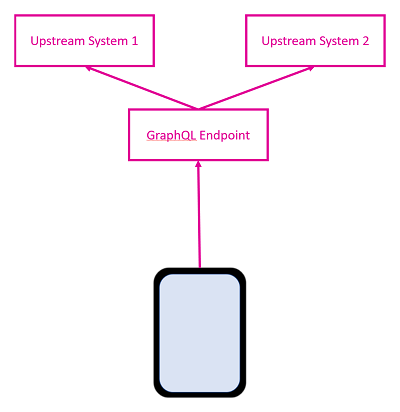
A query in GraphQL looks something like...
{
developers {
name,
competencies {
name,
rating
}
}
}
...with the result taking the form...
{
"data": {
"developers": [
{
"name": "Sam",
"competencies": [
{
"name": "JavaScript",
"rating": 8
},
{
"name": "C#",
"rating": 7
}
]
},
{
"name": "Gary",
"competencies": [
{
"name": "C++",
"rating": "8"
},
{
"name": "Compilers",
"rating": 8
}
]
}
]
}
}The 'types' in a GraphQL endpoint represent abstract domain entities. It shouldn't matter if your server has to build them from a database, an upstream service, or by combining several of these methods. That's an implementation detail. What should be exposed to your users is a consistent set of business objects. As such, GraphQL is type-aware. During creation, you specify the types of your objects, the fields on those objects, their types, and so on. In the example above, developer is a type, name is a field of the developer type. competencies is a field on developer, which has a type of list of competency. rating is a field on the competency type.
As the type system itself is queryable, your API has an aspect of discoverability to it. Not only that, the queries can be validated against the type system for correctness.
Conceptually, the 'graph' aspect of GraphQL is not a database. It is instead the mental model of how the entities in your domain are associated with one another. As an abstract concept, it doesn't map to how the data are stored. GraphQL is a generic mechanism to retrieve data in response to a query. Therefore, it conceptually sits at the same layer as your REST API in the server stack. GraphQL endpoints can happily sit alongside an existing REST API (it's not a competition!), with both interacting with the same underlying persistence/caching layers of your web service.
The Case Study
For the purpose of this blog series, I'm going to be defining a GraphQL API for a fictitious software consultancy. The API's purpose is for the administration of employees, the resourcing of projects, and the maintenance of a skill set of employees. Some of this will be security and permissions-protected too, so that certain functionalities can only be performed by users with specific permissions.
Let's first talk about the relationships between the types in the domain. There is a Developer, who will be assigned a Role at the company. They'll have a list of Competencies and may be assigned a Project. Hey, as we're talking about GraphQL, let's describe this as a graph!
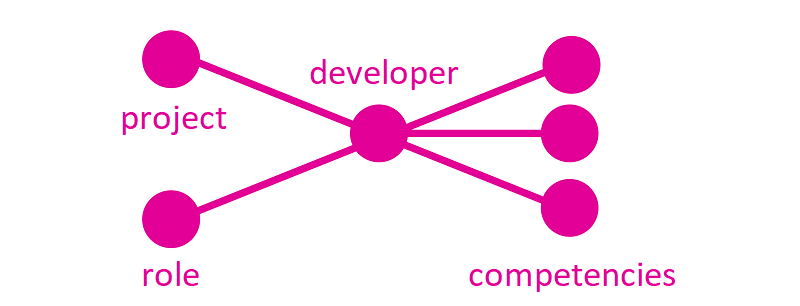
Initially I'll start simple, and from the ground-up. I'll define an in-memory database, and then build it out into using a SQL database. I may make mistakes along the way, but hopefully we'll learn a lot about how to build a GraphQL API!
Setting Things Up
I'll be using NodeJS for this series, so let's start by defining an express server, alongside the graphql layer:
npm install --save express express-graphql graphql
Defining A Schema
To define the GraphQL schema, you need to do two things:
- Specify your types, in GraphQL schema language
- Define resolver functions to retrieve your data
The schema is just a string, passed to the buildSchema function from the graphql package:
schema.js:
import { buildSchema } from 'graphql';
import { getDevelopers, getProjects, roles } from './api';
export const schema = buildSchema('
type Project {
id: String!,
name: String,
description: String
}
type Competency {
name: String,
rating: Int
}
type Developer {
id: String!,
name: String,
competencies: [Competency],
role: Role,
project: Project
}
enum Role {
GRAD, DEV, SENIOR, LEAD
}
type Query {
developers: [Developer],
projects: [Project]
}
');
export const rootValue = {
developers: () => getDevelopers(),
projects: () => getProjects()
};The type system itself is quite easy to grasp. Exclamation marks represent that a field is non-nullable. Lists are represented by square brackets. Enumerated types are just a collection of strings.
The Query type is a special reserved type, which identifies the schema's root query. It represents fields that can be queried at the top level; the root; or a GraphQL query. In this case, I'm exposing a list of Developers and a list of Projects. The rootValue object provides data for both of these fields.
Both the built schema and the root value are exported from this module. These will later be passed to the GraphQL middleware. But for now, let's focus on filling in the data.
Setting Up The Data
The data are stored as in-memory objects in order to keep things simple.
database.js:
import Competency from './competency';
import Developer from './developer';
import Project from './project';
export const roles = {
'GRAD': 'GRAD',
'DEV': 'DEV',
'SENIOR': 'SENIOR',
'LEAD': 'LEAD'
};
export const projects = [
new Project('1', 'Facelift', 'Redesign of the UI'),
new Project('2', 'Trader 2G', 'The second generation of the trading platform'),
new Project('3', 'Market Data', 'Implementation of market data API')
];
export const developers = [
new Developer('1', 'Sam', [ new Competency('JavaScript', '8'), new Competency('C#', '7') ], roles.SENIOR, '1'),
new Developer('2', 'Gary', [ new Competency('Java', '6'), new Competency('C++', '8') ], roles.LEAD, '2'),
new Developer('3', 'Chris', [ new Competency('Java', '7'), new Competency('JavaScript', '6') ], roles.DEV, '3')
];For the domain types, such as Developer, Project and Competency, I can define some ES6 classes. When a class is returned for a type in a GraphQL schema, any fields that match a class variable with the same name are auto-resolved. Additionally, if there's a method name with the same name as a field from the schema, it will be called whenever that field is requested.
For incredibly simple objects like the Project and Competency types, this means that all the work is done in the constructors.
competency.js:
class Competency {
constructor(name, rating) {
this.name = name;
this.rating = rating;
}
}
export default Competency;project.js:
class Project {
constructor(id, name, description) {
this.id = id;
this.name = name;
this.description = description;
}
}
export default Project;The Developer class is more interesting, as it contains a dynamic and asynchronous resolver. To simulate some form of latency, I've implemented a custom method for returning a developer's assigned project, based on an id that is passed in. The GraphQL JavaScript implementation supports promises natively. When the return type of a field is a promise, the library will wait for all promises to resolve before sending a response to the client. That's as simple as wrapping a (synchronous) API call in a promise.
developer.js:
import { getProject } from './api';
class Developer {
constructor(id, name, competencies, role, projectId) {
this.id = id;
this.name = name;
this.competencies = competencies;
this.role = role;
this.projectId = projectId;
}
project() {
return new Promise(resolve => {
resolve(getProject(this.projectId));
});
}
}
export default Developer;Exposing the data to GraphQL
There are some classes for the data, and a file that collects all of that data together. Next, I'll define an API file, whose job it is to export the raw data sets, but also defines some common query functions on this data. The Developer class uses one of these - to look up a project from a given ID:
api.js
import { developers, projects } from './database';
export const getDevelopers = () => developers;
export const getProjects = () => projects;
export const getProject = id => projects.find(p => p.id === id);Eventually, the in-memory database will be removed with a real database, but ideally this API file should remain as-is. Its purpose is simply to provide a degree of separation between the API surface from its underlying implementation.
Earlier, the schema.js file provided its root value object by calling some of the methods that are defined in the api.js file.
Running the Server
The main file will be responsible for setting up the express server on the spedcified port. It also has the graphiql interactive environment built-in, which allows us easily query the endpoint in a visual editor.
index.js
import express from 'express';
import graphQLHTTP from 'express-graphql';
import path from 'path';
import { schema, rootValue } from './data/schema';
const GRAPHQL_PORT = 8080;
const app = express();
app.use('/', graphQLHTTP({
graphiql: true,
pretty: true,
schema,
rootValue
}));
const server = app.listen(GRAPHQL_PORT, () => {
console.log(`GraphQL server running on http://localhost:${GRAPHQL_PORT}`);
});In the package.json for the project, let's define a script to start up the server, using npm start:
{
...
"scripts": {
"start": "babel-node ."
},
...
}Next Steps
It's very simple to create a GraphQL endpoint. In the next post, I'll swap out the in-memory database with a real database, to investigate how GraphQL performs and integrates with a more complete back-end stack. Later on, I'll add some more data as the fictitious consultancy grows as a business. I'll also allow for mutations to alter the server's data.