Pick'Em Lambda Functions
The Pick'Em app is starting to take shape!
First, I set up (most of) the infrastructure. Following on from that I defined a single table schema with DynamoDB. Next up is to define the "API Layer", as in, a bunch of API calls the UI application can make to do some stuff.
The appeal of serverless functions (Lambda, in AWS lingo) to a cheapskate like me is that I pay for exactly what I use, and I only use resources when there's a demand for them. I don't need to maintain my own EC2 instance in the cloud and everything that comes with that (patching, building AMIs, deploying code). Lambda abstracts this away into workloads that run essentially on-demand, on compute resource provisioned and managed by the cloud provider on your behalf. When demand falls back, the resources are decommissioned.
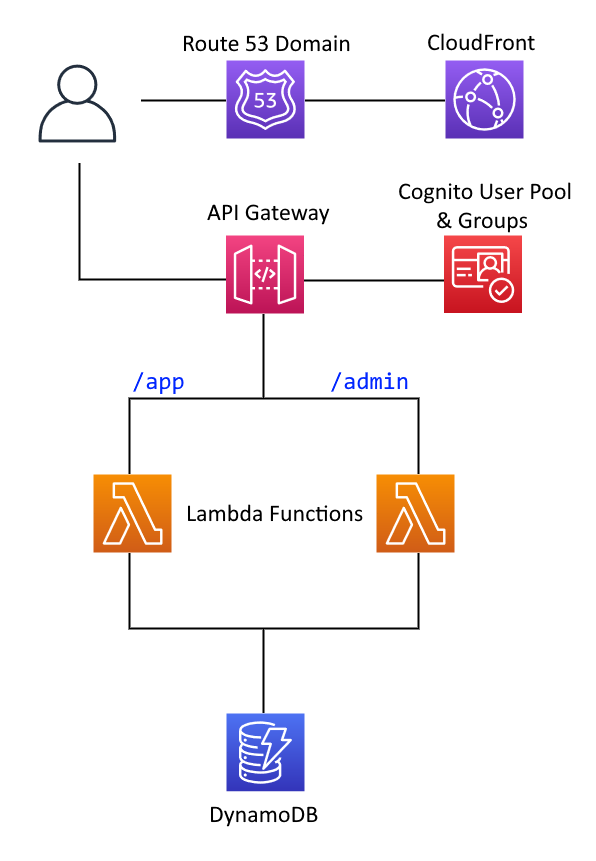
Working with serverless requires a slightly different way of thinking, as you need to consider what event triggers your function. Returning to my original architecture diagram, the events will essentially be HTTP calls on two paths: /app for user-facing traffic, and /admin for administrator API calls, forwarded from the API Gateway that I provisioned:
Using Node 20.x
Lambda functions created using amplify add function live in their own subdirectory of the amplify/backend/function directory.
Amplify creates nodejs18.x runtimes for NodeJS lambdas, which is the current LTS version (at the time of writing). I wanted to use a later version of Node, so I modified the Resources.LambdaFunction.Runtime property in each Lambda's CloudFormation template to be "Runtime": "nodejs20.x", located within the <lambdaname>-cloudformation-template.json file.
Using ES Modules
Further, the default setup is to use CommonJS for the JavaScript module format. To change this, I added type: module into the package.json of the lambda function. I then used Visual Studio Code to format the index.js file in each application to ES Modules import/export syntax.
import awsServerlessExpress from 'aws-serverless-express';
import app from './app.js';
/**
* @type {import('http').Server}
*/
const server = awsServerlessExpress.createServer(app);
/**
* @type {import('@types/aws-lambda').APIGatewayProxyHandler}
*/
export function handler(event, context) {
console.log(`EVENT: ${JSON.stringify(event)}`);
return awsServerlessExpress
.proxy(server, event, context, 'PROMISE')
.promise;
};When I generated these Lambda functions from the command line, I used the template that sets up an Express server - all that setup code lives in app.js. I performed the same code transformation there too.
What's the Point of Express in Serverless?
Convenience. Express is well suited to a long-lived server running on NodeJS and behaves as expected - you define a bunch of routes to listen to and handle requests/responses appropriately. In serverless, the idea of setting up something to listen on a port for multiple incoming API requests admittedly seems a bit wonky - but it comes with advantages too. It's familiar to me. aws-serverless-express handles proxying incoming events and producing outgoing responses from the HTTP requests/responses from express. Further, I can logically group a bunch of API calls into a single lambda function, which reduces the number of deployables I need to manage.
Accessing DynamoDB
I wrote a 'wrapper' around the DynamoDBClient for ease of use. It ensures consistent logging and reduces the boilerplate needed to interact with the database. Unmarshalling from DynamoDB-style JSON occurs automatically.
import { DynamoDBClient, GetItemCommand, PutItemCommand, QueryCommand } from '@aws-sdk/client-dynamodb';
import { marshall, unmarshall } from '@aws-sdk/util-dynamodb';
const client = new DynamoDBClient({ region: process.env.TABLE_REGION });
const db = {
get: async function (params) {
console.log(JSON.stringify(params));
const { Item } = await client.send(new GetItemCommand(params));
return unmarshall(Item);
},
put: async function (params) {
console.log(JSON.stringify(params));
await client.send(new PutItemCommand(params));
},
query: async function(params) {
console.log(JSON.stringify(params));
const { Items } = await client.send(new QueryCommand(params));
return Items.map(unmarshall);
}
};I don't want to expose the DynamoDB key attributes on the outgoing objects returned to the UI. By defining an object (clearedDBKeys) which has each of these properties explicitly set to undefined, I can later use JavaScript's Object Spread syntax to effectively unset these properties on an object.
const clearedDBKeys = {
PK: undefined, SK: undefined, GSI_PK: undefined, GSI_SK: undefined
};Accessing the User's ID
For some API calls I need to resolve the calling user's username, such as when storing predictions or retrieving a user's score. To retrieve it, I reach out to the Cognito Identity Provider service and query for the username, based on a user's unique id. The user ID is available on the incoming request context, it just needs to be regex'ed out of a longer string. I've declared this as a reusable, asynchronous function as it needs to make a request out:
import { CognitoIdentityProviderClient, ListUsersCommand } from '@aws-sdk/client-cognito-identity-provider';
const IDP_REGEX = /.*\/.*,(.*)\/(.*):CognitoSignIn:(.*)/;
const getUserId = async (req) => {
const authProvider = req.apiGateway.event.requestContext
.identity.cognitoAuthenticationProvider;
const [, , , userId] = authProvider.match(IDP_REGEX);
const client = new CognitoIdentityProviderClient({
region: process.env.REGION
});
const response = await client.send(new ListUsersCommand({
UserPoolId: process.env.AUTH_USERPOOLID,
AttributesToGet: ['sub'],
Filter: `"sub"="${userId}"`,
Limit: 1
}));
return response.Users[0].Username;
};Let's Implement Some Functions!
Rather than go through every API call I've implemented, I'll just cover one set of GET and POST pairs.
Get an Event (With User Predictions)
Referring back to the data access patterns in the previous post:
Get Event Listings and Predictions (PK = EVENT#id, Filter = attribute_not_exists(belongsto) Or belongsto = user)
First, defining a route. It uses the above getUserId function and calls a service function, getEvent, then returning the result as JSON. I use this pattern extensively, so all the route handlers look similar: get the input data, call a service function, return the result as JSON. Separation of concerns!
app.get('/app/predict/:event', async function (req, res) {
try {
const event = req.params.event;
const userId = await getUserId(req);
const data = await getEvent(event, userId, true);
res.json(data);
} catch (error) {
onError(req, res, error);
}
});The getEvent function queries the database and formats the results for consumption in the UI.
Recall that DynamoDB can store multiple items under the same partition key, even when they're different types. The function unmarshalls the DynamoDB JSON object into a plain ol' JavaScript object and then iterates over the items. The type attribute is switched over to determine the appropriate formatting and placement on the returned object.
export async function getEvent(event, user, onlyPredictions) {
const params = {
TableName: PICKEM_TABLE,
ExpressionAttributeValues: {
':pk': { 'S': `EVENT#${event}` }
},
KeyConditionExpression: 'PK=:pk',
ScanIndexForward: false,
};
if (onlyPredictions) {
params.ExpressionAttributeValues[':belongsto'] = { 'S': `USER#${user}` };
params.FilterExpression = "attribute_not_exists(belongsto) Or belongsto = :belongsto";
}
const items = await db.query(params);
const entry = {
event: null,
matches: [],
predictions: {},
scores: []
};
if (items) {
return items.reduce((acc, item) => {
const type = item.type;
switch (type) {
case 'event':
acc.event = {
...item,
...clearedDBKeys
};
break;
case 'match':
acc.matches.push({
...item,
...clearedDBKeys
});
break;
case 'prediction':
if (item.belongsto === `USER#${user}`) {
acc.predictions = item.predictions;
}
acc.scores.push({
name: item.belongsto.replace('USER#', ''),
points: item.points,
mcorrect: item.mcorrect,
});
break;
default:
break;
}
return acc;
}, entry);
} else {
return entry;
}
}If you're asking "why does getEvent have a boolean onlyPredictions parameter?", it's a good question. It comes from another data access use case:
Get Event Listings, Scores and User's Predictions (PK = EVENT#id, ScanIndexForward=false)
When an event has finished and scored, I want to display the event matches, the user's predictions, and then the scores for every participating user. This will let a user see which matches they predicted and compare their performance with the competition.
Save A User's Predictions
The expected POST body is an object of predictions, where a property refers to the unique id (the uuid) of the event, and its value refers to the index of the predicted winning team:
{
"event-id": 1,
"another-event-id": 0
}The route handler for the POST call is simple, following the structure of getting the data needed, calling a service function, and then returning. All that's needed here is a HTTP 200.
app.post('/app/predict/:event', async function(req, res) {
try {
const event = req.params.event;
const predictions = req.body;
const userId = await getUserId(req);
await savePredictions(event, userId, predictions);
res.sendStatus(200);
} catch (error) {
onError(req, res, error);
}
});The savePredictions service function issues a PUT call to DynamoDB. This is a prediction entity. Its score is initially set to 0 (padded to 000) and the predictions attribute stores the map of predictions from the POST body. I always use a PUT operation as this satisfies both creating and updating the predictions items. I don't know up front if it exists.
export async function savePredictions(event, user, predictions) {
const params = {
TableName: PICKEM_TABLE,
Item: marshall({
PK: `EVENT#${event}`,
SK: `SCORE#000#${user}`,
type: 'prediction',
belongsto: `USER#${user}`,
predictions,
mcorrect: 0,
points: 0
}),
};
await db.put(params);
}What's Next?
Naturally, there's more to my serverless code to what's written here. I hope this has been a sufficient generation of having a Lambda function respond to an incoming HTTP request, do some stuff, interact with other AWS constructs, and return a response.
We've the infrastructure, database schema, and API layers in place. Next up is the frontend! My next post in this series will cover building a frontend application using VueJS.