Connecting SQLite to GraphQL
📖 Click here for a fully-worked example of the code in this blog post
Previously, I created a GraphQL endpoint that returned data for a fictitious software consultancy firm. I discussed the reasoning behind this approach, but the implementation was slightly smoke-and-mirrors. Instead of a using real data source, I cheated and created a static, in-memory file. Let's swap that implementation out with some real database technology!
Setting up the Database
Searching for Node SQL clients yielded several possible options. Initially, the sqlite3 package seemed like the best choice. Upon installation it installs the necessary binaries and provides a simple API to set up and query a SQLite database. However, I found the API too simple - in particular, it had quite a heavy focus on using callbacks for running database code, which is a tad old-fashioned and cumbersome to work with.
Instead I opted for the similarly-named sqlite package. It wraps the sqlite3 library but provides a promise-based API. Furthermore I found its support for SQL-based migration files to be a more maintainable way of handling the setup of the database.
Defining the Data
Time to put the data into the database! When designing the structure I opted to normalise the data as much as possible. In the spirit of the single responsibility principle, things that can change for different reasons exist in different tables of the database. Therefore a developer's project assignments live in a separate table, as do the list of competencies recorded by a particular developer. These are linked by foreign keys. Sure, it makes the SQL queries to query the data more complex, but it keeps the overall database more maintainable for the future.
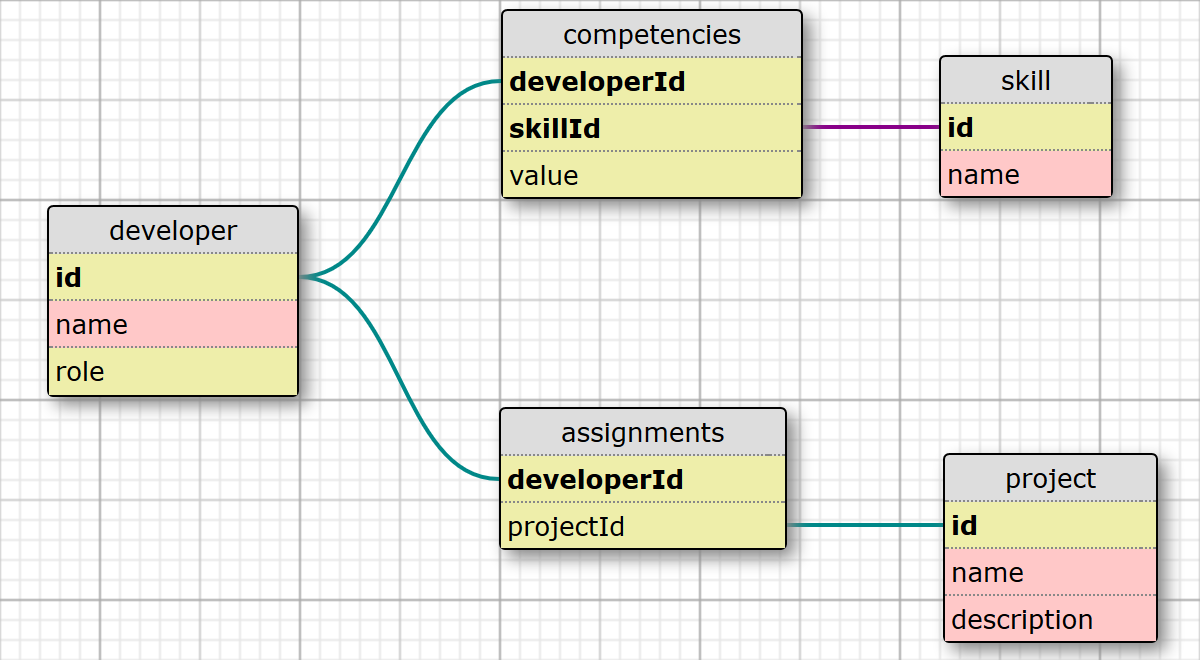
The sqlite package includes a database migrations feature, which lets you define a numbered series of .sql files containing both upgrade and downgrade scripts. This allows your database to evolve over time, accommodating for rollbacks where necessary. These live within a root-level directory named 'migrations'. To begin, I'll only need one file to create the database tables and populate them with data:
migrations/001-initial-schema.sql
-- Up
CREATE TABLE project (
id INTEGER PRIMARY KEY,
name TEXT,
description TEXT
);
CREATE TABLE developer (
id INTEGER PRIMARY KEY,
name TEXT,
role INT
);
CREATE TABLE skill (
id INTEGER PRIMARY KEY,
name TEXT
);
CREATE TABLE assignments (
developerId INTEGER,
projectId INTEGER,
FOREIGN KEY(developerId) REFERENCES developer(id) ON DELETE CASCADE,
FOREIGN KEY(projectId) REFERENCES project(id) ON DELETE CASCADE,
PRIMARY KEY(developerId)
);
CREATE TABLE competencies (
developerId INTEGER,
skillId INTEGER,
value INTEGER,
FOREIGN KEY(developerId) REFERENCES developer(id) ON DELETE CASCADE,
FOREIGN KEY(skillId) REFERENCES skill(id) ON DELETE CASCADE,
PRIMARY KEY(developerId, skillId)
);
# There's a lot of INSERT INTO statements here!
-- Down
DROP TABLE project
DROP TABLE developer
DROP TABLE skill
DROP TABLE assignments
DROP TABLE competencies
Hooking up to the Database
Now I will need to set up the database connection and find a way to ensure that the GraphQL resolvers have a means to query the data.
To recap: For each field in a graphql schema, you're expected to define a function that returns some value. For convenience, if you return an object for a field, then sub-fields that exist as properties will be auto-resolved. I used this to great success by defining a class for each type in my schema, with properties on the class corresponding to GraphQL fields for that type, with class-level methods for any asynchronous data resolution.
The main server.js file is the most appropriate place to do any initial setup, for here it's possible to create the database and then create the express server with the GraphQL middleware. When creating the database you specify whether you'd like it to be in-memory, or persisted to a file. I've chosen in-memory still as this keeps things simple. As the sqlite package is promise-based I can chain together then statements. First, calling sqlite.migrate() will cause the migration scripts to be run in sequential order. Once completed, the express server can be established.
There's one change in how the GraphQL middleware is constructed. The database connection is effectively a global entity. But it's bad form to simply make the sqlite instance a global field, so to instead make sure that resolver functions are able to access it by reference, upon setting up the GraphQL middleware it is possible to pass in a context object. Mine is a simple wrapper around the database, proxying two of its accessor functions.
server.js %} import express from 'express'; import graphQLHTTP from 'express-graphql'; import sqlite from 'sqlite'; const { schema, rootValue } = require('./data/schema');
const GRAPHQL_PORT = 8080;
sqlite.open(':memory:', { cached: true }) .then(() => sqlite.run('PRAGMA foreign_keys=on')) .then(() => sqlite.migrate()) .then(() => { const graphQLApp = express(); graphQLApp.use('/', graphQLHTTP({ graphiql: true, pretty: true, schema, rootValue, context: { db: { get: (...args) => sqlite.get(...args), all: (...args) => sqlite.all(...args), run: (...args) => sqlite.run(...args) } } }));
graphQLApp.listen(GRAPHQL_PORT, () => {
console.log(
GraphQL server is now running on http://localhost:${GRAPHQL_PORT}
);
});
})
.catch(e => console.error(e));
An interesting point to make is that I need to turn on the enforcement of foreign key constraints by immediately running a `PRAGMA` statement. For backwards-compatibility the enforcement of foreign keys is not enabled by default in SQLite v3, something which will be addressed in v4.
The context object is passed into every resolver function as an argument. Here's what my root query field resolver functions now look like:
*schema.js:*
```javascript
import { buildSchema } from 'graphql';
import { getDevelopers, getProjects } from './api';
export const schema = buildSchema(`...`);
export const rootValue = {
developers: (obj, ctx) => getDevelopers(ctx),
projects: (obj, ctx) => getProjects(ctx)
};
Recall that all data was retrieved by calling methods defined in a file named api.js. For the smoke-and-mirrors implementation it would call through to a file containing some static, in-memory JavaScript objects held within database.js. Now there's no need for the fake database file as api.js can simply make calls against the real database. The purpose of api.js remains the same - it is effectively an incredibly naïve ORM mechanism, making database calls and turning them into objects.
api.js
import Competency from './competency';
import Developer from './developer';
import Project from './project';
export const getDevelopers = ctx =>
ctx.db.all('SELECT id, name, role FROM developer')
.then(result => result.map(r => new Developer(r.id, r.name, r.role)));
export const getProjects = ctx =>
ctx.db.all('SELECT id, name, description FROM project')
.then(result => result.map(r => new Project(r.id, r.name, r.description)));
export const getProject = (id, ctx) =>
ctx.db.get('SELECT id, name, description FROM project WHERE id = $id', { $id: id })
.then(result => new Project(result.id, result.name, result.description));
export const getCompetenciesForDeveloper = (id, ctx) =>
ctx.db.all(
`SELECT s.name, c.value FROM competencies c LEFT JOIN skill s ON (c.skillId = s.id) WHERE c.developerId = $id`,
{ $id: id })
.then(result => result.map(r => new Competency(r.name, r.value)));
A Change to the Model
To demonstrate how GraphQL supports fields being resolved asynchronously, in the Developer type I made getting the assigned Project asynchronous. It was simply a promise that resolved immediately, creating a Project from an id. Now that there's an actual database in place, this can be replaced with a real database lookup, searching for the project referenced in the assignments table. Similarly, the list of Competencies are no longer available up-front, as in the database they're stored within a separate competencies table. These will require a further lookup too.
developer.js:
import { getCompetenciesForDeveloper, getProject } from './api';
import { toRole } from './role';
class Developer {
constructor(id, name, role, projectId) {
this.id = id;
this.name = name;
this.role = toRole(role);
this.projectId = projectId;
}
competencies(ctx) {
return new Promise(resolve => {
resolve(getCompetenciesForDeveloper(this.id, ctx));
});
}
project(ctx) {
return new Promise(resolve => {
resolve(getProject(this.projectId, ctx));
});
}
}
export default Developer;When building this I noticed that there was some further work required to get enums to behave correctly. My schema defines the Role enum in terms of some string values: GRAD, DEVELOPER, SENIOR, LEAD. I stored roles in the developer table using the convention of having a unique integer represent each possible value. So GRAD = 0, DEVELOPER = 1 and so on. It was necessary to define a lookup function to convert an integer to a string so that GraphQL would correctly identify the returned value as valid for the Role enum type:
role.js
const Role = {
GRAD: 'GRAD',
DEV: 'DEV',
SENIOR: 'SENIOR',
LEAD: 'LEAD'
};
const roleMappings = {
0: Role.GRAD,
1: Role.DEV,
2: Role.SENIOR,
3: Role.LEAD
};
export const toRole = val => roleMappings[val];
export default Role;Next Steps
I was pretty pleased to discover that it was quite easy to drop-in a database to my application without too many hiccups along the way. The two main gotchas were discovering the ability to pass through a context object (and then working out which argument this corresponded to in the resolver functions), and also the necessity of having to manually convert an integer-based enum to a string-based one.
In the next post I'll start looking at adding some interactivity to the GraphQL API. Particularly, I'll be covering how to pass arguments to GraphQL fields, and how to allow a client to change the data in the API, which is known as a mutation.